Skardi
![]()
What is Skardi?
Skardi is an open-source data platform for AI agents — Pick any data in your stack (CSV, Parquet, S3, Postgres, MySQL, SQLite, MongoDB, Redis, Iceberg, Lance, SeekDB) and Skardi turns it into something an agent can query, join, write to, and operate on autonomously — through SQL, REST, shell, and (soon) MCP.
Skardi is Spark for Agents. Spark gave data teams a single engine over every storage format; the agent era needs the same, shaped for how agents actually work — schemas agents can read, outputs agents can parse, tools agents can discover, and writes agents can trust.
skardiCLI — federated SQL + parameterized pipelines as shell commands. Drop it into any agent that has a Bash tool (Claude Code, Cursor, custom loops) and it's wired.skardi-server— two peer surfaces on one engine: online serving (declarative SQL pipelines as parameterized REST endpoints) and offline jobs (async batch writes into Lance or any read-write DB, with atomic commit + run ledger).- Soon — skills generation for auto-discovery, MCP binding for non-Claude hosts, a first-class memory primitive (structured + vector + FTS + provenance + TTL), lineage, and agent-scoped governance.
Beta. Skardi is under active development. APIs may move. Hit us on Discord if you want to co-design a POC.
Why "Spark for Agents"?
Agents don't lack intelligence — they lack data autonomy. Hand an LLM a raw schema dump and it hallucinates; hand it a bag of bespoke REST endpoints and it gets lost; hand it a vector store and it still can't JOIN. The gap isn't the model. The gap is that today's data stack was designed for humans writing queries, not agents calling tools.
Skardi closes that gap with three deliberate choices:
- One engine over every source. DataFusion-based single-node federation. An agent can
JOINa CSV against Postgres against a Lance dataset in one query. - Online serving. Parameterized SQL served synchronously as REST endpoints; the low-latency path every agent tool call hits.
- Offline jobs. The same SQL shape run asynchronously into a durable destination, with a run ledger, atomic commit, and submit / poll / cancel.
Read the full narrative in docs/spark_for_agents.md.
Architecture
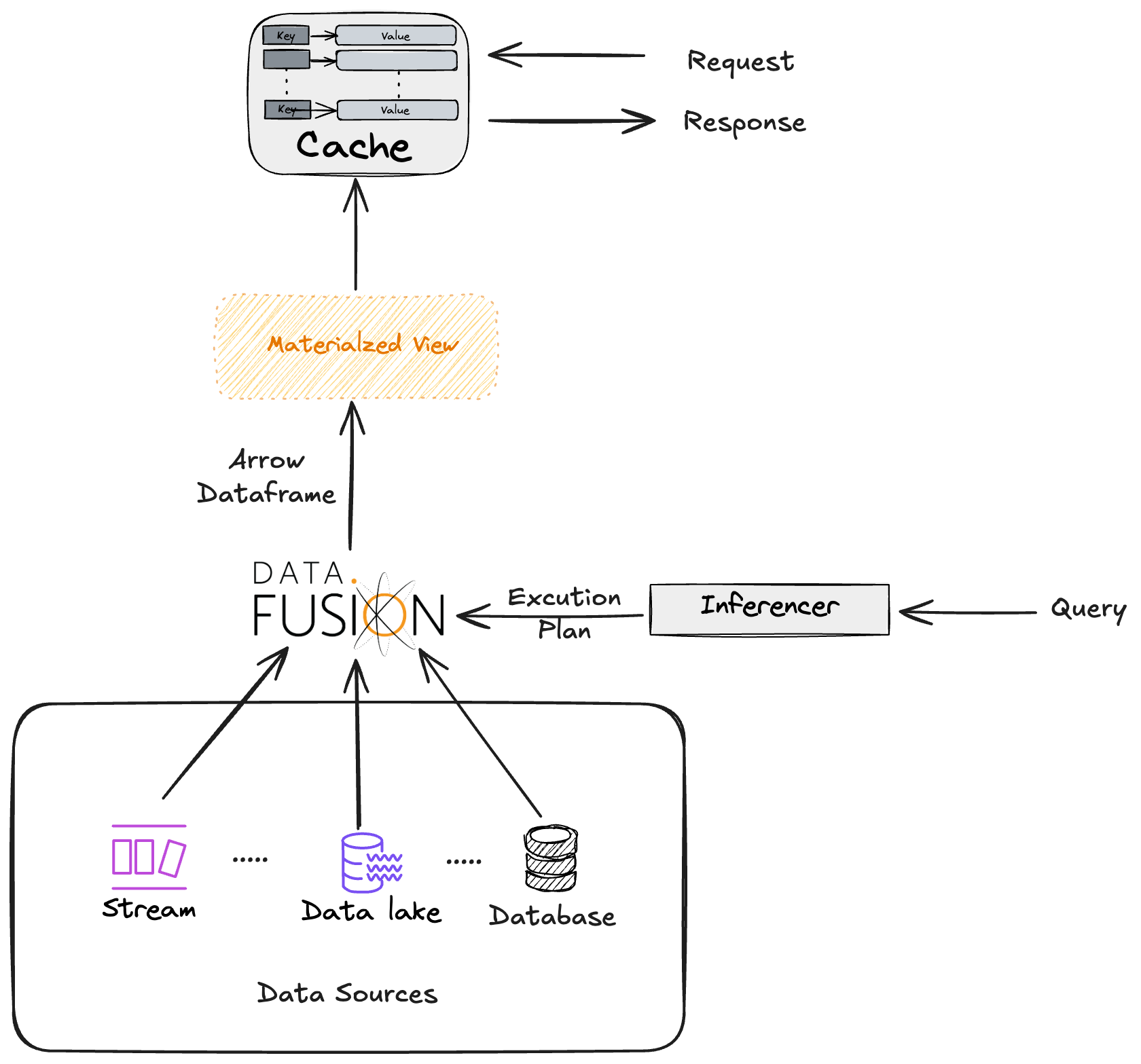
What's already in the box
Engine
- Federated SQL across every major source — CSV, Parquet, JSON, S3 / GCS / Azure, Postgres, MySQL, SQLite, MongoDB, Redis, Iceberg, Lance, SeekDB — all joinable in one query.
- Register by table or by catalog — pick per source: expose a single named table, or load an entire Postgres / MySQL / SQLite database as a DataFusion catalog. One config line either way.
- Vector search — native KNN via Lance,
pg_knn(pgvector),sqlite_knn(sqlite-vec), SeekDB HNSW. - Full-text search — Lance BM25 inverted indexes,
pg_fts,sqlite_fts, SeekDB native FULLTEXT. - Inline embeddings —
candle()UDF (GGUF / Candle / remote embed APIs) directly inside SQL, so content + vector stay on the same row atomically. - ONNX inference —
onnx_predictUDF for inline model predictions in SQL. - Hybrid search — RRF merge of FTS + KNN in plain SQL (see llm_wiki demo).
Agent-facing surfaces
- CLI
skardi run <pipeline>— parameterized pipeline invocation from any shell; works in Claude Code / Cursor / any agent with a Bash tool. - User-defined aliases —
skardi grep "…"→run wiki-search-hybrid. Collapses multi-line SQL into agent-ergonomic verbs. - Online serving — YAML → parameterized HTTP endpoint, with an inferred request / response schema and a built-in dashboard.
- Offline jobs — async pipeline that commits to Lance or a DB destination, with a SQLite run ledger and submit / poll / cancel. (#98)
Ops
- Session auth — drop-in user auth via better-auth backed by SQLite.
- Observability — OpenTelemetry traces / metrics / logs with a pre-configured Grafana stack.
- Docker + pre-built binaries — Linux x86_64 / ARM64, macOS ARM64.